
이 글은 Deep RL Course를 학습하고 정리한 글입니다.
가치 기반 방법 (Value-based methods)
가치 기반 방법에서는 상태를 입력으로 받아 해당 상태에서 기대할 수 있는 값을 출력하는 가치 함수(Value Function)를 학습합니다.
상태의 가치(Value of a state)는 에이전트가 특정 상태에서 시작해 이후 특정 정책(Policy)을 따른다고 가정할 때 기대할 수 있는 할인된 보상의 합입니다.
$$v_{\pi} (s) = \mathbb{E}_{\pi} [R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+2} + \gamma^3 R_{t+3} + \cdots | S_t = s]$$
하지만 가치 기반 방법에서는 정책을 학습하지 않고 가치 함수를 학습합니다. 그렇다면 "정책을 따른다"는 것은 무엇을 의미할까요?
최적 정책을 찾는 방법
강화학습의 궁극적인 목표는 최적 정책 $\pi ^*$를 찾는 것입니다. 최적 정책을 찾기 위한 방법에는 두 가지가 있습니다.
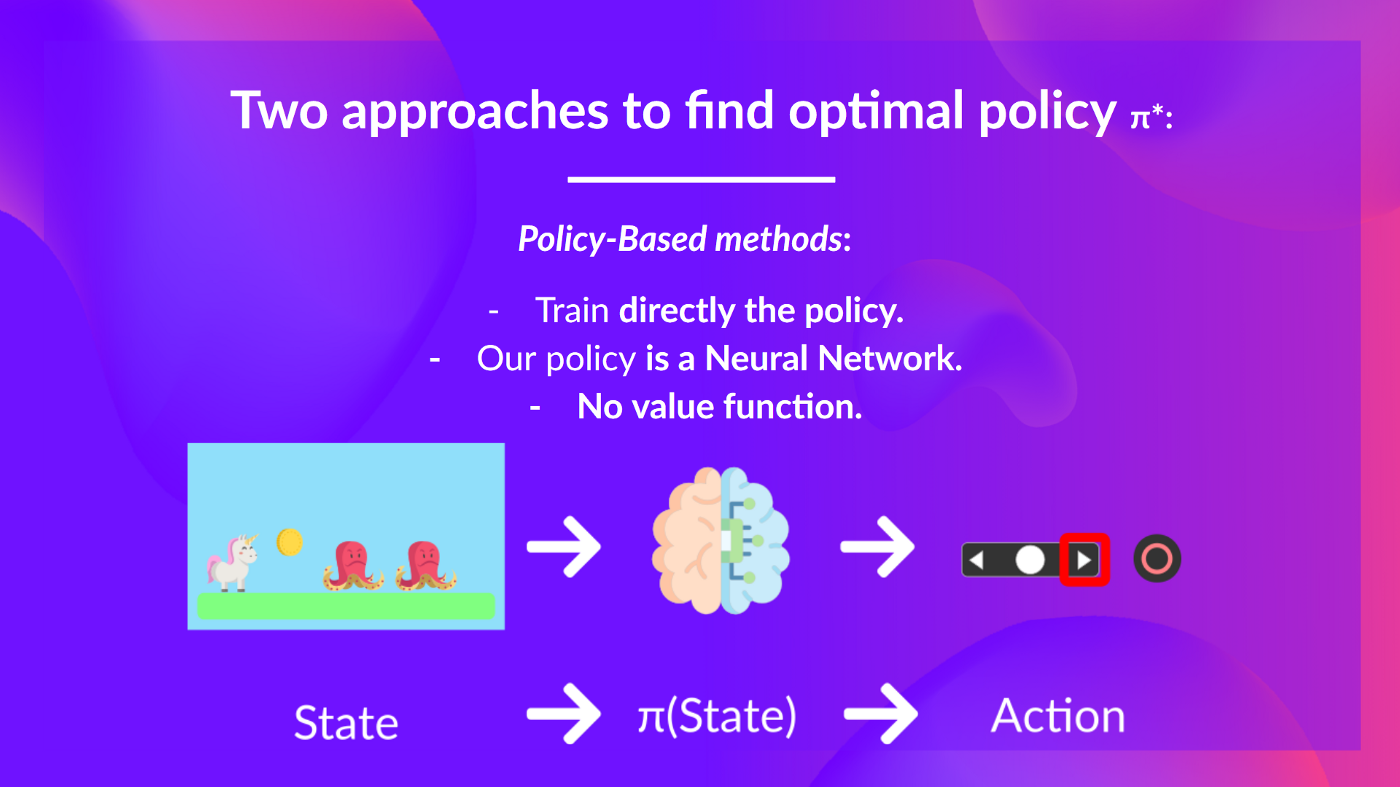
1. 정책 기반 방법(Policy-based methods)
정책 기반 방법은 상태가 주어졌을 때 선택할 행동 또는 행동의 확률 분포를 출력하는 정책을 직접 학습합니다. 이 경우에는 가치 함수는 존재하지 않습니다. 따라서 정책 기반 방법에서는 정책의 동작을 사람이 직접 정의하지 않고 학습 과정을 통해 자동으로 정의됩니다.
2. 가치 기반 방법(Value-based methods)
가치 기반 방법에서는 상태 또는 상태-행동 쌍에 대한 가치를 출력하는 가치 함수를 학습합니다. 학습된 가치 함수에 따라 행동을 선택할 정책이 간접적으로 정의됩니다.
정책이 학습되거나 훈련되지 않기 때문에 정책의 동작을 사전에 정의해야 합니다. 예를 들어, 주어진 가치 함수를 기반으로 항상 가장 큰 보상을 가져오는 행동을 선택하도록 탐욕 정책(Greedy Policy) 정의할 수 있습니다.

상태 가치 함수 (State-Value Function)
상태 가치 함수는 주어진 정책 $\pi$ 하에서 특정 상태 $s$에서 시작하여 에이전트가 얻을 수 있는 기대 반환을 계산합니다.

에이전트가 상태 값이 -7인 상태에서 시작하고 탐욕 정책을 따른다고 가정합니다. 탐욕 정책은 현재 상태에서 가장 높은 가치를 제공하는 행동을 선택합니다. 따라서, 에이전트는 -7 → 오른쪽(-6) → 오른쪽(-5) → 오른쪽(-4) → 아래쪽(-3) → 아래쪽(-2) → 오른쪽(-1) → 오른쪽(치즈)로 이동합니다.

행동 가치 함수 (Action-Value Function)
행동 가치 함수는 특정 상태 $s$에서 특정 행동 $a$를 취한 후 정책 $\pi$를 계속해서 따를 때 기대할 수 있는 총 반환을 계산합니다.


문제점
상태 가치 함수나 행동 가치 함수를 계산하려면 에이전트가 특정 상태 또는 상태-행동 쌍에서 시작하여 얻을 수 있는 모든 보상의 합을 계산해야 합니다. 이는 모든 가능한 경로와 보상을 합해야 하므로 계산 비용이 매우 높아질 수 있습니다.
'강화학습' 카테고리의 다른 글
| [Deep RL Course] 몬테카를로 vs 시간차 학습 (0) | 2025.01.06 |
|---|---|
| [Deep RL Course] 벨만 방정식 (0) | 2025.01.05 |
| [Deep RL Course] Huggy 훈련하기 (1) | 2025.01.03 |
| [Deep RL Course] Huggy 작동 방식 (1) | 2024.12.31 |
| [Deep RL Course] 심층 강화학습 에이전트 훈련하기 (0) | 2024.12.30 |